Computation Caching
It's costly to rebuild and retest the same code over and over again. Nx uses a computation cache to never rebuild the same code twice.
In order not to recompute something twice, Nx needs two things:
- To store the results of the computation.
- To know when you've computed something you've already computed before.
There are three things that tell Nx if something has been computed before:
Source Code Cache Inputs
The result of building/testing an application or a library depends on the source code of that project and all the source codes of all the libraries it depends on (directly or indirectly). It also depends on the configuration files like package.json, workspace.json, nx.json, tsconfig.base.json, and package-lock.json. The list of these files isn't arbitrary. Nx can deduce most of them by analyzing our codebase. Few have to be listed manually in the implicitDependencies property of nx.json.
1{
2 "npmScope": "happyorg",
3 "implicitDependencies": {
4 "global-config-file.json": "*"
5 },
6 "projects": {},
7 "tasksRunnerOptions": {
8 "default": {
9 "options": {
10 "cacheableOperations": ["build", "test", "lint", "e2e"]
11 }
12 }
13 }
14}
Runtime Cache Inputs
Things like the version of NodeJS, whether you are running Windows or not, can affect the results of the computation but cannot be deduced statically. Those have to be configured manually too.
1{
2 "npmScope": "happyorg",
3 "implicitDependencies": {},
4 "projects": {},
5 "tasksRunnerOptions": {
6 "default": {
7 "options": {
8 "cacheableOperations": ["build", "test", "lint", "e2e"],
9 "runtimeCacheInputs": ["node -v", "echo $IMPORTANT_ENV_VAR"]
10 }
11 }
12 }
13}
Args Cache Inputs
Finally, in addition to Source Code Cache Inputs and Runtime Cache Inputs, Nx needs to consider the arguments: For example, nx build shop and nx build shop --prod produce different results.
Note, only the flags passed to the builder itself affect results of the computation. For instance, the following commands are identical from the caching perspective.
nx build myapp --prod
nx build myapp --configuration=production
nx run-many --target=build --projects=myapp --configuration=production
nx run-many --target=build --projects=myapp --configuration=production --parallel
nx affected:build # given that myapp is affectedIn other words, Nx does not cache what the developer types into the terminal. The args cache inputs consist of: Project Name, Target, Configuration + Args Passed to Builders.
If you build/test/lint… multiple projects, each individual build has its own cache value and is either be retrieved from cache or run. This means that from the caching point of view, the following command:
nx run-many --target=build --projects=myapp1,myapp2is identical to the following two commands:
nx build myapp1
nx build myapp2
All Cache Inputs
So the combination of Source Code Cache Inputs, Runtime Cache Inputs, and Args Cache Inputs determine the result of the computation. If anything in the source changes, Nx needs to recompute. If anything in runtime changes, Nx needs to recompute. But if you have already computed the results, the stored artifacts are used.

What is Cached
Nx works on the process level. Regardless of the tools used to build/test/lint/etc.. your project, the results is cached.
Nx sets up hooks to collect stdout/stderr before running the command. All the output is cached and then replayed during a cache hit.
Nx also caches the files generated by a command. The list of folders is listed in the outputs property in workspace.json.
1{
2 "projects": {
3 "myapp": {
4 "root": "apps/myapp/",
5 "sourceRoot": "apps/myapp/src",
6 "projectType": "application",
7 "architect": {
8 "build": {
9 "builder": "@nrwl/web:build",
10 "outputs": ["dist/apps/myapp"],
11 "options": {
12 "index": "apps/myapp/src/app.html",
13 "main": "apps/myapp/src/main.tsx"
14 }
15 }
16 }
17 }
18}
If the outputs property is missing, Nx defaults to caching the appropriate folder in the dist (dist/apps/myapp for myapp and dist/libs/somelib for somelib).
Local Computation Caching
By default, Nx uses a local computation cache. Because the word "cache" appears in the description, the phrase "artifact caching" comes to mind. But this isn't the right way to think about it. What Nx does is really computation memoization. Nx doesn't choose to use or not use the cached value. There are no versions. It is transparent: Nx skips the computation only when running the computation would have produced the same result.
Nx stores the cached values only for a week, after which they are deleted. To clear the cache, delete the cache directory, and Nx creates a new one the next time it tries to access it.
Distributed Computation Caching
The computation cache provided by Nx can be distributed across multiple machines. Nx Cloud is a SAAS product that allows you to share the results of running build/test with everyone else working in the same workspace. Learn more at https://nx.app. You can also distribute the cache manually using your own storage mechanisms.
Skipping Cache
Sometimes you want to skip the cache, such as if you are measuring the performance of a command. Use the --skip-nx-cache flag to skip checking the computation cache.
nx build myapp --skip-nx-cache
nx affected:build --skip-nx-cache
Customizing the cache location
The cache is stored in node_modules/.cache/nx by default. To change the cache location, update the cacheDirectory option for the task runner:
1{
2 "npmScope": "happyorg",
3 "implicitDependencies": {},
4 "projects": {},
5 "tasksRunnerOptions": {
6 "default": {
7 "options": {
8 "cacheableOperations": ["build", "test", "lint", "e2e"],
9 "cacheDirectory": "/tmp/nx"
10 }
11 }
12 }
13}
Example
Say you are the first one building some shop app.
The nx build shop command builds the app by invoking Webpack under the hood. It creates a hash key using the combination of Source Code Cache Inputs, Runtime Cache Inputs, and Args Cache Inputs. Nx then checks its local cache to see if this combination has already been built on this machine. If the answer is "no", it checks the Nx Cloud cache (if the workspace is connected to it) to see if someone else has already built it. If the answer is "no", it runs the build.
It sets up hooks to collect stdout/stderr, and after the build is complete, it stores the command line output into a file in the local cache. It also copies the produced files there. After that it spawns a separate process to upload the artifacts to the Nx Cloud cache.
If you rerun the same command, Nx finds the artifact in the local cache and replays the output from it and restores the necessary files.
Someone else on the team check outs the changes, and is trying to build nx build shop. As before Nx uses Source Code Cache Inputs, Runtime Cache Inputs, and Args Cache Inputs to get the computation hash key. It then checks the local cache. The results won't be there, so it checks the remote cache. It finds the record there, so it downloads it into its local cache first, prints the stored stdout/stderr, and copies the files to the place where they would normally be created. The terminal output and the created files are exactly the same as if the person ran the computation themselves.
The "someone else" in this scenario doesn't have to be a real person. For instance, every CI run likely use a different agent. When the agents can all access the same remote cache, the CI time goes down drastically.
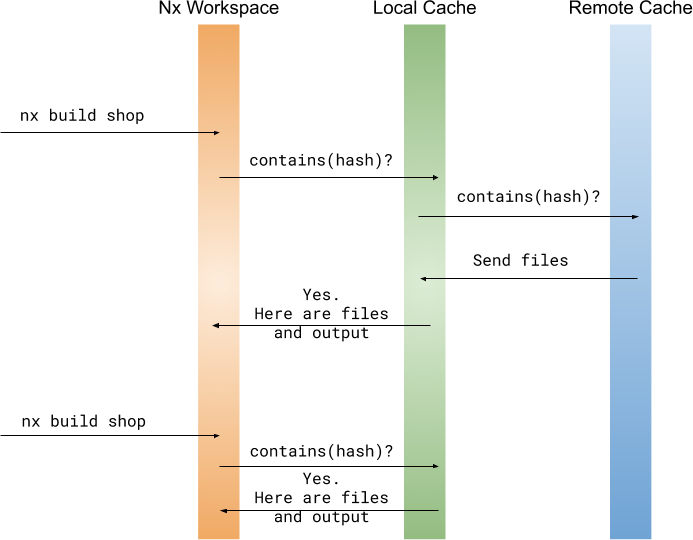
The nx test shop command, which in this case uses Jest, works similarly. The combination of Source Code Cache Inputs, Runtime Cache Inputs, and Args Cache Inputs determines the computation. The command won't emit any files, but the terminal output bes captured and stored.
Caching and Affected
In addition to the caching, which works against the current state of the codebase and the environment, Nx also looks at the code change itself, and figures out what can be broken by it, and only rebuilds and retests what is affected. Why use both?
Affected and caching are used to solve the same problem: minimize the computation. But they do it differently, and the combination provides better results than one or the other.
The affected command looks at the before and after states of the workspaces and figures out what can be broken by a change. Because it knows the two states, it can deduce the nature of the change. For instance, this repository uses React and Angular. If a PR updates the version of React in the root package.json, Nx knows that only half of the projects in the workspace can be affected. It knows what was changed--the version of React was bumped up.
Caching simply looks at the current state of the workspace and the environment (such as the version of Node) and checks if somebody already ran the command against this state. Caching knows that something changed, but because there is no before and after states, it doesn't know the nature of the change. In other words, caching is a lot more conservative.
If you only use affected, the list of projects that are be retested is small, but if you test the PR twice, all the tests are run twice.
If you only use caching, the list of projects that are be retested is larger, but if you test the PR twice, the tests are only run the first time.
Using both allows you to get the best of both worlds. The list of affected projects is as small as it can be, and you never run anything twice.